

Inhalt dieses Beitrags
Suchmaschinenoptimierung zeigt nicht selten wahre Stilblüten der Technik. Gestern hatte sich das Businessnetzwerk LinkedIn für kurze Zeit selber mit der www.-Domain komplett selber aus dem Index geworfen.
www.linkedin.com komplett deindexiert
LinkedIn Sichtbarkeit
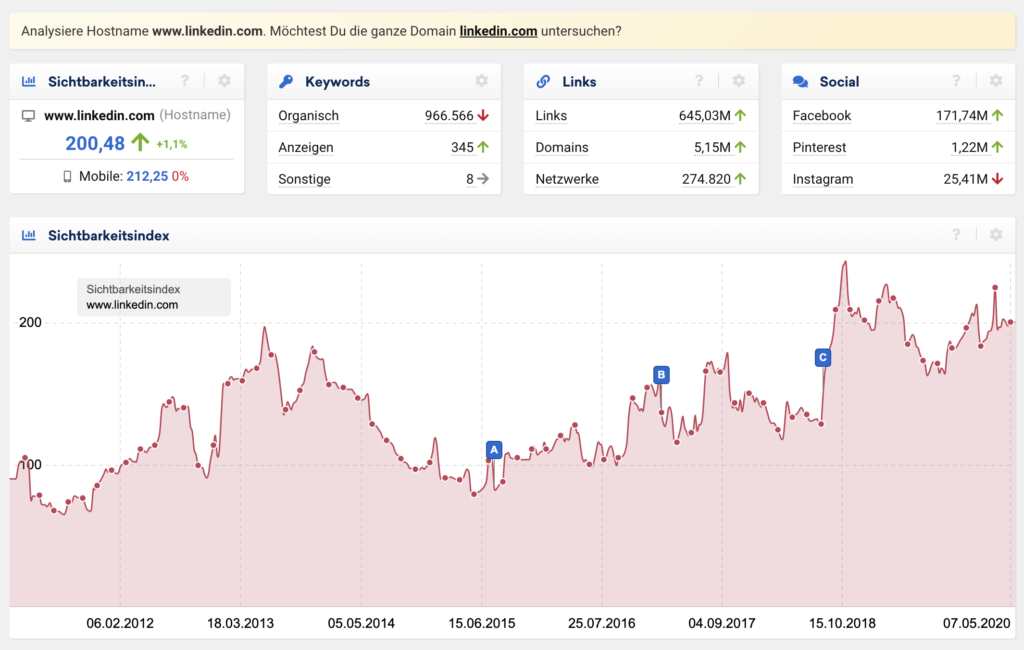
Der geneigte Suchmaschinenoptimierer geht dabei (und vor allem auf Grund der Firmengröße) natürlich erst einmal davon aus, dass das ein geplanter Move war. Bei der Betrachtung des Quellcodes und der Sichtbarkeitswerte kamen dann aber doch sehr schnell Zweifel an der Sinnhaftigkeit der Deindexierung auf. Alleine in den USA hat www.linkedin.com eine Sichtbarkeit von fast 200 nach SISTRIX und im Quelltext war kein NOINDEX oder ähnliches zu finden.
gewollte Deindexierung oder SEO-Unfall?
Im Laufe des Tages wurde relativ schnell klar, dass hier wohl ein kapitaler Fehler passiert ist und die Deindexierung mit Sicherheit nicht gewollt war. Welcher SEO würde eine Sichtbarkeit von 200 riskieren ohne dabei ein entsprechendes Weiterleitungskonzept und Index-Steuerung vorzunehmen?
Twitter hilft – immer
Wer John Müller auf Twitter nicht folgt, ist selbst schuld! Mit seiner lockeren (wenn auch nicht immer ganz transparenten) Art, hat er den Vorfall dann auch direkt kommentiert und Kollege Barry Schwarz hat gekonnt geantwortet. Aber seht selber:
URL-Removal Tool?
Man kann nur spekulieren, aber laut dem Tweet von John Müller scheint da jemand bei linkedin.com mit dem URL-Removal-Tool in der GSC gespielt zu haben. Und da Google auch nur eine Maschine ist, wurde die Anweisung prompt befolgt und alle Inhalte wurden aus dem Index verbannt.
Oder doch robots.txt?
Ein Twitter-User hatte vermutet, dass die Deindexierung an einer fehlerhaften robots.txt liegen könnte, weil dort scheinbar „user-agent: *, disallow: /“ zu sehen war. Aktuell ist das aber nicht reproduzierbar und im Übrigen hätte das auch nicht zu einer kompletten Deindexierung von hunderten Millionen URLs geführt. Diese Directive in der robots.txt besagt ja nur, dass der Crawler die Seiten nicht besuchen/crawlen darf. Nicht mehr und nicht weniger. Crawl Management != Index Management.
Zurück auf Los
Der Fehler wurde natürlich sehr schnell bemerkt und LinkedIn hat auch direkt reagiert. Die Domain wurde wieder zur Indexierung frei gegeben und alle URLs waren auch sofort wieder im Google-Index, denn Google löscht nicht einfach so, sondern behält die Daten 180 Tage, d.h. die Linked-Ergbnisse wurden nur ausgeblendet. Das hat zur Folge, dass alle 238 Millionen URLs auch direkt wieder sichtbar wurden, nachdem der Fehler behoben wurde.




