

Inhalt dieses Beitrags
Suchmaschinenoptimierung ist eine eher komplexe Online Marketing Disziplin, denn es gilt auf hunderte verschiedener Faktoren zu achten. Unbemerkte HTTP-Status- und Server-Probleme gehören dazu. Sie können nicht nur Deine Rankings nachhaltig negativ beeinflussen, sondern sind für Deine Besucher oftmals auch ein Problem. Vor allem dann, wenn Du sie nicht bemerkst!
Der Toolanbieter SEMrush hat dazu eine tolle Studie gemacht, die die Häufigkeit der Status- und Serverprobleme schön aufzeigt.
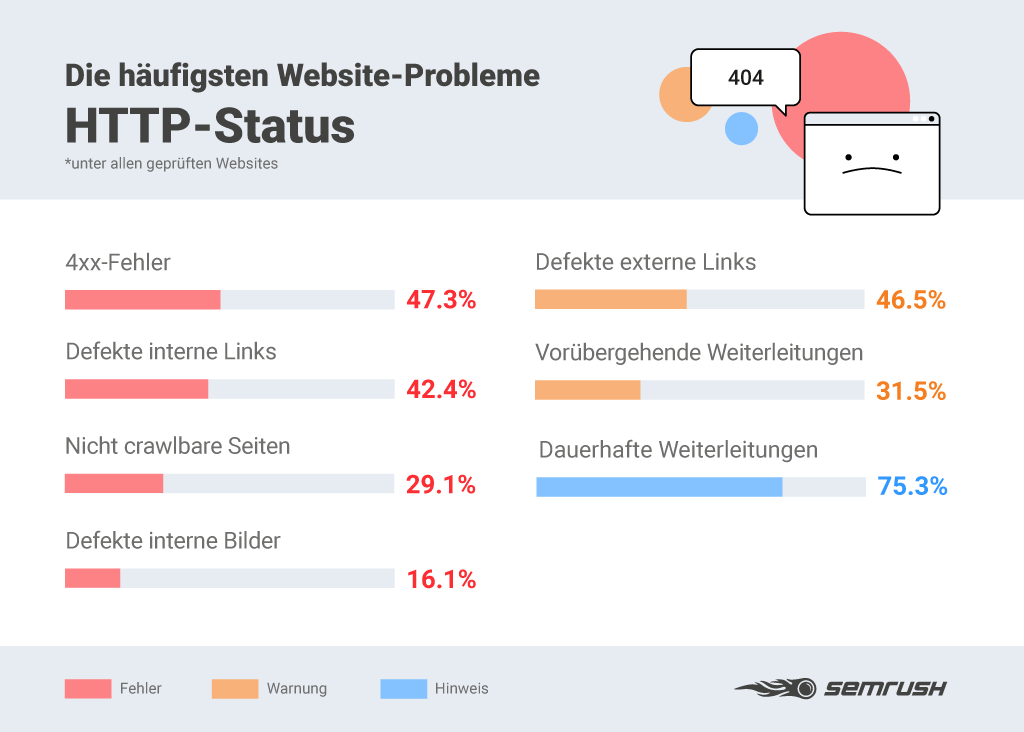
HTTP-Status- und Server-Probleme
Welche Probleme das im Einzelnen sein können, möchten wir Dir an dieser Stelle kurz erklären.
400er Fehler
Die Fehler aus der 400er-Kategorie oder eigentlich besser 4xx zeigen Dir, dass Du entweder defekte, nicht erreichbare oder verlorene URLs hast. Am geläufigsten ist die 404-Fehlermeldung – not found. Dein Besucher hat versucht eine URL aufzurufen und der Webserver kennt diese aber nicht. Das kommt vor, wenn der User z.B. eine URL selber in den Browser getippt hat oder über einen Link auf eine nicht mehr existente Ressource/URL gekommen ist.
404-Fehlermeldungen sind sehr häufig und eigentlich auch normal. Laut Studie von SEMrush zeigen über 47% aller untersuchter Webseiten diese Fehler. Aber wenn sie auf einer Domain gehäuft auftreten, kann das für Google ein negatives Signal sein: schlecht gepflegte Webseite, die die Technik nicht im Griff hat. Dahin möchte Google dann irgendwann keine Besucher mehr schicken und schiebt Deine Rankings nach unten. Daneben gibt es aber auch noch zahlreiche andere Fehlermeldungen aus der 4er-Klasse, die sogenannte „Client-Fehler darstellen.
Für eine gute Übersicht kannst Du die entsprechende Wikipedia-Seite aufrufen: https://de.wikipedia.org/wiki/HTTP-Statuscode . Hier findest Du ein saubere Übersicht.
Übrigens: Du kannst die 404-Fehler auf Deiner Webseite eigentlich recht einfach finden. Entweder Du schaust Dir das Fehlerreporting in der Google Search Console an, oder Du wertest Deine Logfiles aus. Für WordPress-Nutzer gibt es zudem jede Menge Plugins, die das ebenfalls anbieten.
Wenn Du Deine 404-Fehler gefunden hast, solltest Du diese schnellstmöglich beheben. Entweder indem Du fehlende URLs wieder herstellst, oder diese gegebenenfalls statt mit 404 in 410er Statuscodes umwandelst. Damit sagst Du dem Crawler, dass diese Ressource endgültig weg ist – GONE. Falls die 404-Fehlerseite durch einen falsch gesetzten Link entstanden ist (und das passiert leider häufig), dann solltest Du den Webmaster fragen, ob er den Link ändert. Falls das nicht möglich, kannst Du die nicht existente URL per 301-Weiterleitung auf das korrekte Ziel umleiten.
Defekte interne Links
Ein weiterer und ebenfalls sehr häufiger Fehler sind defekte interne Links. Die SEMrush-Studie hat ergeben, dass über 42% der analysierten Webseiten solche kaputten internen Verlinkungen aufweisen. Auch hier resultieren 2 große Probleme aus diesem Fehler:
- Suchmaschinencrawler können den Links zwar folgen, landen dann aber wiederum auf 404-Seiten, weil das Linkziel nicht (mehr) existent ist. Das kann 2 Ursachen haben: entweder die Ziel-URL wurde entfernt oder geändert, oder die Zieladresse hinter dem Link wurde falsch gewählt bzw. falsch geschrieben.
- Defekte interne Links sind auch für die Besucher der Webseite frustrierend und führen in der Regel zu Absprüngen und Abbrüchen bzw. verkürzen die Aufenthaltsdauer innerhalb der Webseite. Und die wiederum ist eben auch ein Rankingfaktor. Zu viele defekte interne Links können sich damit auch negativ auf die Rankings auswirken.
Auch dafür kannst Du Tools wie SEMrush oder auch Screaming-Frog und viele andere nutzen. Danach ist wieder Handarbeit angesagt, um die defekten Links zu beheben.
Defekte externe Links
Das Internet lebt von Verlinkungen. Gäbe es diese nicht, wäre es kein Netz! Deshkab verlinken Websites auch gerne mal „nach draussen“, d.h. auf andere interessante Webseiten oder entsprechende Quellen. Das Problem dabei: eine verlinkte Ressource ist jetzt aktuell und unter einer uniquen Adresse zu finden, aber das kann sich immer mal auch ändern.
Stell Dir vor Du verlinkst einen tollen und informativen Blogbeitrag auf einer anderen Domain und lieferst Deinen Lesern damit einen Mehrwert. Ein paar Jahre (manchmal auch nur Wochen oder Monate) später macht diese Webseite einen Relaunch, bei der sich auch deren URL-Struktur ändert oder alter Content wird einfach gelöscht. Genau dann hast Du plötzlich einen defekten externen Link auf Deiner Webseite. Das kommt übrigens mit 46% auch recht häufig vor und damit kein Einzelfall.
Aber auch hier kommt der Crawler irgendwann an seine Akzeptanzgrenze und auch Deine Leser ärgern sich, wenn sie auf solche toten Links klicken. Deshalb solltest Du im Sinne der Besucher, und auch um den Crawler glücklich zu machen, Deine externen Links immer mal wieder in Intervallen prüfen und notfalls anpassen oder abändern.
Vorübergehende Weiterleitungen
Vorübergehende Weiterleitungen, oder auch sogenannte temporäre Redirects, werden eingesetzt, wenn URLs zeitweilig nicht verfügbar sind oder sein sollen. Onlineshops setzen diesen Statuscode (in der Regel Code 302) gerne und häufig ein. Immer dann wenn z.B. ein Produkt gerade nicht mehr verfügbar ist. Leider werden 302-Weiterleitungen dann ganz gerne auch einfach mal vergessen. Und das sollte natürlich eigentlich nicht passieren, denn wenn die Weiterleitung permanent erfolgt, sollte dies mit Statuscode 301 erfolgen (redirect permanent).
Laut der Studie sind das immerhin über 31%, wobei hier nicht explizit gesagt wird, über welchen Zeitraum die Messung erfolgt ist, d.h. es kann durchaus sein, dass ein Teil der 302-Redirects korrekt ist.
Dauerhafte Weiterleitungen
Weiterleitungen sind nicht perse immer gleich Fehler und haben durchaus auch eine technische Berechtigung. Gerade bei Relaunches und einer Umstrukturierung von Navigationen (mit denen nicht selten auch die URL-Struktur geändert wird) muss man sogar zwingend dauerhafte Weiterleitungen einsetzen. Nicht nur, um dem Crawler die neue URL mitzuteilen, sondern auch um wichtigen eingehenden Linkjuice auf die neuen Dokumente und URLs zu verteilen. In der Studie wird der Wert mit über 75% angegeben. Das klingt viel, ist aber interpretationsbedürftig und nicht unbedingt insgesamt fehlerhaft.
Trotzdem ist es wichtig die eigenen Redirects immer im Auge zu haben und nötigenfalls auch von zeit zu zeit anzupassen und zu überarbeiten. Außerdem können zu viele Redirects auch zum Performanceproblem werden, weshalb man sie nur immer mit Bedacht einsetzen sollte.
Pro-Tipp: ganz schlecht sind sogenannte Redirect-Ketten! Die entstehen manchmal automatisch, wenn sich Ziel-URLs schon mehrfach geändert haben.
Nicht crawlbare Seiten
Immerhin noch über 29% der analysierten Domains haben nicht crawlbare Seiten und sperren z.B. den Googlebot damit aus. Das ist nicht grundsätzlich falsch, denn der Crawler muss/soll nicht immer auch alle Inhalte finden und lesen. Trotzdem ist der Wert durchaus interessant, denn häufig passiert das eben leider auch ungewollt und dann verspielt der Webmaster damit auch diverse Potentiale.
Zum einen wird ein nicht crawlbares Dokument nicht indexiert und kann damit auch keine Rankings erzielen oder zur Sichtbarkeit beitragen. Zum anderen enthält man der Suchmaschine möglicherweise wichtige Inhalte vor, die dann in der kontextuellen und semantischen Gesamtbewertung fehlen.
Defekte interne Bilder
Die Verwendung von Bildern sollte immer sorgsam bedacht werden, denn sie sind einer der häufigsten Gründe für lange Ladezeiten. Interne Bilder liegen im Webspace an speziellen Speicherorten und werden mit dem <img>-Tag in den Content eingebunden. Ändert sich der Speicherort (source bzw. src) sind die Bilder plötzlich defekt. Im schlimmsten Fall wird ein Image-Folder umbenannt und alle dort verorteten Bilder werden plötzlich nicht mehr auf der Webseite angezeigt. Ein weiter Fehler bzw. defekte interne Bilder entstehen auch häufig, wenn Webmaster von http: zu https: wechseln und die Bildpfade im <img>-Tag absolut gesetzt sind.
Da Bilder ein wichtiges Content Element darstellen und auch im Rahmen des Layouts eine Rolle spielen, sollten Webmaster auf diese möglichen Fehler achten, um ein optimales Nutzererlebnis zu gewährleisten. Laut Studie haben immerhin noch knapp über 16% der Webseiten defekte interne Bilder.
Fazit
Es ist nicht nur aus Sicht der Suchmaschinenoptimierung wichtig, seine Status- und Server-Fehler immer im Auge zu haben. Auch der User wird es am Ende des Tages danken.




